In this post we are going to learn a lot of things about puppet catalog, catalog compilation and how it is utilized by puppet master , It is a great know how for anyone interested in puppet and also a great resource for someone appearing for puppet dev/admin interview.
What is puppet catalog anyways ?
A catalog is a yaml document that describes the state of a puppet managed server at any given time, it contains all managed resources for that server, as well as any interdependencies between listed resources.
It looks like below, for complete catalog file content, please visit https://github.com/faintdream/misc/blob/master/node.yaml
1 | --- !ruby/object:Puppet::Resource::Catalog |
If you look closely you will figure that couple of classes are ready to be applied to the server like buildtools, apache::download hierasample & so on. but the question arises how did puppet master know that these resources are required to be applied to the server running puppet agent ? Simply put node itself informs a lot about what all it needs directly and indirectly through manifests.
Tip : to generate the catalog for your puppet managed node ( including puppet master) , simply run following command.
1 | [root@node misc]# puppet catalog download |
For a puppet master to create node specific catalog, puppet master depends on following sources for truth,
- Agent provided data
- External Data
- Manifest/Modules
Agent provided data
This is the set of information collected from the node running puppet agent.
- Node’s name same as node’s cert name and is embedded in request URI /puppet/v3/catalog/ubuntu.example.com?environment=production . if you remember when we run
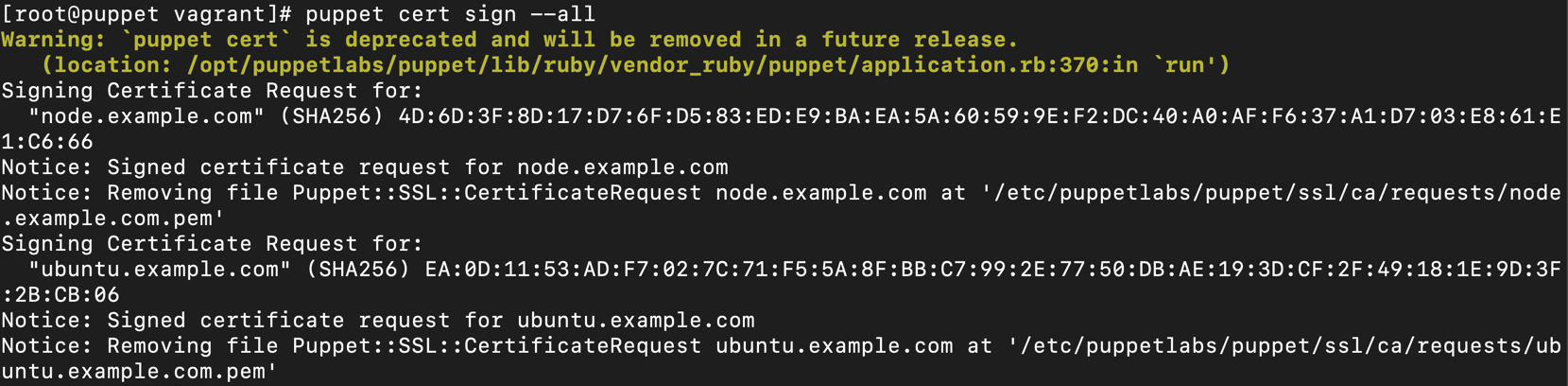
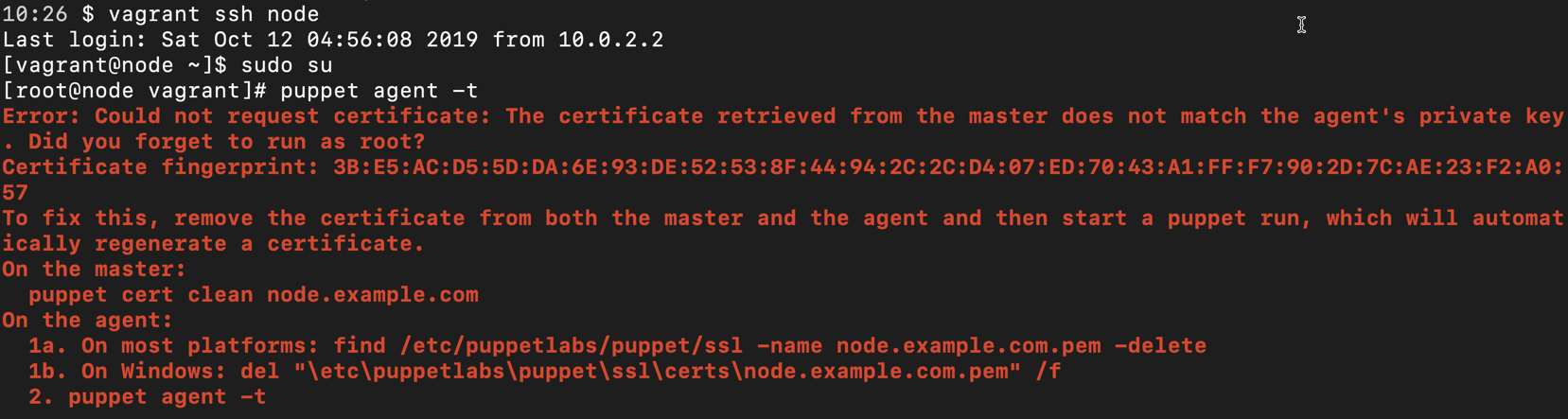
puppet agent -tfor the first time, it creates as ssl certificate for itself and this certificate needs to be authorized by puppet master for both to be able to talk to each other ( https communication) - Node certificate contains some additional information used for policy based autosigning & adding new trusted facts.
[note: not applicable to masterless/stand alone architecture] - Node’s facts including builtin as well as custom facts, some of these facts we use quite often in puppet code like $[os][family] , $[trusted][certname].
- Before requesting catalog , the agent requests its environment from the master, if master provides none, the environment is picked from agent’s config [/etc/pupetlabs/puppet.conf], this means the environment set on agent side is given least priority, so dont assume you will set something agent side and it will persist if there is already an environment set by the puppet master.
External data
Puppet uses two types of external data
- ENC - This is the data collected from Enhanced Node classifier or popularly known as ‘ENC’. ENC script can be carved out of your favourite programming language( python & ruby being most sought after in this use case) as long as it is designed to look for passed value and capture corresponding node information and returning the same to puppet master. The captured data is in the form of node object and may contain classes, node’s top scope variable, class configuration parameters/Environment information from master.
- Data from other sources, which can be invoked from main manifest or classes or defined types in modules. This kind of data includes,
- Exported resources from PuppetDB.
- The result of functions, which can access data sources including Hiera or an external configuration management database.
Manifest/Modules
manifests contain DSL (Declarative Style Language) that describes state of resource on target server.
catalog compilation process
A brief run down of what all happens during catalog compilation process,
- node running puppet agent sends its certificate, facts & environment to puppet master.
- puppet master requests node_terminus for a node object.
- If the node_terminus is ‘plain’ , an empty node object is returned.
- If the node_terminus is ‘exec’, a request is sent to ENC ( 3rd party script/software) to provide node specific data like what classes are to be applied etc.
- If node_terminus is ‘ldap’. Node data is fetched from ldap db.
- Set variables from node object, facts and certificate
- This data is used by manifests in subsequent compilation stage.
- Node facts are set as top scope variable.
- The node’s facts are set in $facts hash( it remains immutable after this for the corresponding node) .
- Some data from certificate header is set in the protected $trusted hash.
- Any variable provided by the puppet master are set .
- manifest evaluation
- Puppet parses the main manifest.
- If there are node definition in the manifests, it must find a matching current node name for a catalog to compile, otherwise it fails compilation.
- Code outside the node definition is evaluated ( modules/classes/templates), resources in the code are added to the catalog and any classes declared in the code are loaded.
- If a node is found in main manifest, code inside the node definition is evaluated at node level and any classes declared are loaded
- Evaluates classes from module .
- If the classes were declared but not defined, puppet master looks at $modulepath to load the classes .
- Evaluate classes from node object
- The process is the same as how classes are loaded from node definition or loading classes from modules, the only difference here is that the applicable classes were populated from node object.
- Puppet parses the main manifest.
That’s pretty much it , once the catalog is compiled it is thrown back to the node running agent in order to get the changes applied,